DiT: Diffusion Transformer and Diffusion Models#
This page covers the diffusion-based models in TorchWM: DDPM for image generation, DiT for scalable transformer-based diffusion, and DIAMOND for diffusion world models in reinforcement learning.
Based on papers:
Denoising Diffusion Probabilistic Models (Ho et al., 2020)
Scalable Diffusion Models with Transformers (Peebles & Xie, 2023)
DIAMOND: Diffusion as a Model of Environment Dreams (Alonso et al., 2024)
Overview#
Diffusion models learn to generate data by reversing a gradual noising process. In TorchWM, diffusion models serve two purposes:
Image/video generation (DDPM, DiT): High-quality unconditional or conditional sample generation.
World models for RL (DIAMOND): Diffusion-based dynamics models that predict future observations.
graph LR
A["Data x₀"] --> B["Forward: q(x_t|x₀)"]
B --> C["..."]
C --> D["x_T ~ N(0, I)"]
D --> E["Reverse: p_θ(x_{t-1}|x_t)"]
E --> F["..."]
F --> G["Generated x₀"]
DDPM: Denoising Diffusion Probabilistic Models#
Forward Process#
The forward (diffusion) process gradually adds Gaussian noise to data over T
timesteps according to a fixed variance schedule:
We can sample x_t directly from x_0:
where α_t = 1 - β_t and \bar{α}_t = ∏_{s=1}^{t} α_s. Using the
reparameterization trick:
Reverse Process#
The reverse process learns to denoise. Starting from pure noise x_T ∼ N(0, I):
Training Objective#
The simplified DDPM loss trains the model to predict the noise ε at each timestep:
x0 = batch # clean images
t = randint(0, T) # random timestep
eps = randn_like(x0) # random noise
xt = sqrt(alpha_bar[t]) * x0 + sqrt(1 - alpha_bar[t]) * eps
eps_pred = model(xt, t) # predict noise
loss = mse(eps_pred, eps) # simple noise-prediction loss
loss.backward()
Sampling#
x = torch.randn(shape) # pure noise
for t in reversed(range(T)):
eps_pred = model(x, t) # predict noise
x = (x - sqrt(1 - alpha_bar[t]) * eps_pred) / sqrt(alpha_bar[t])
if t > 0:
x += sigma[t] * torch.randn_like(x)
return x # generated image
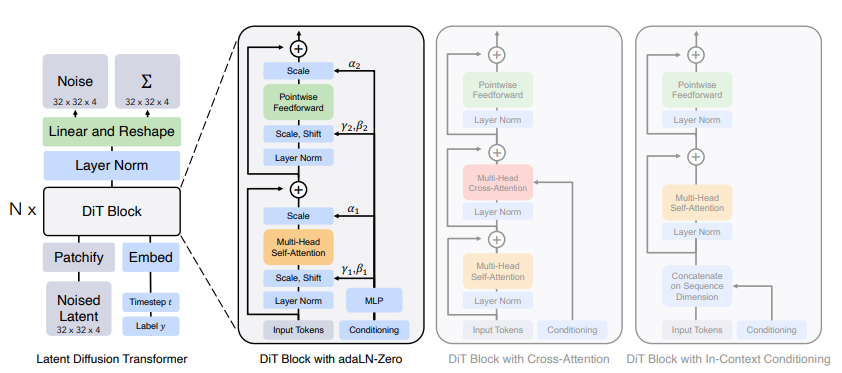
DiT: Diffusion Transformer#
DiT replaces the U-Net backbone with a Vision Transformer for noise prediction, providing better scalability and global context.
Architecture#
graph TD
A["Noisy image x_t"] --> B["Patchify: (C,H,W) → (N,D)"]
C["Timestep t"] --> D["Timestep embedding"]
D --> E["AdaLN modulation"]
B --> F["DiT Block × depth"]
E --> F
F --> G["..."]
G --> H["Output head: (N,D) → (C,H,W)"]
H --> I["Predicted noise ε_θ"]
Patch Embedding#
The input x_t ∈ ℝ^{C×H×W} is split into patches of size P and linearly embedded:
For a 32×32 CIFAR-10 image with P=4: 64 tokens of dimension D.
Timestep Conditioning (AdaLN)#
DiT uses Adaptive Layer Normalization (AdaLN) to condition on the diffusion
timestep. The timestep embedding predicts the scale γ and shift β for each
block’s layer norm:
Variant |
Scheme |
Parameters |
Speed |
|---|---|---|---|
AdaLN |
γ, β per block |
Low |
Default |
AdaLN-Single |
Shared γ, β |
Very low |
Fastest |
AdaLN-Diagonal |
γ, β + diagonal scaling |
Medium |
Medium |
DiT Block#
No cross-attention — DiT is typically unconditional or class-conditional via AdaLN.
Training#
from torchwm import DiTConfig, get_dit_config
cfg = get_dit_config(
DATASET="CIFAR10",
BATCH=128,
EPOCHS=100,
IMG_SIZE=32,
WIDTH=384,
DEPTH=6,
)
Sampling (Generation)#
# Start from random noise, iteratively denoise
for t in reversed(range(T)):
ε = model(x_t, t) # Predict noise
x_{t-1} = x_t - sqrt(1-alpha_bar_t) * ε
Classifier-Free Guidance#
For conditional generation:
where w is guidance weight (typically 1-10).
DIAMOND: Diffusion World Models#
DIAMOND applies diffusion models to world modeling for reinforcement learning. Instead of predicting latent states (Dreamer) or discrete tokens (IRIS), it predicts future observations using a diffusion denoising process.
Architecture#
graph TD
A["Past 4 frames"] --> B["Cond. encoder"]
C["Action a_t"] --> B
B --> D["Conditioning embedding c"]
E["Noisy next frame x_t + ε"] --> F["Diffusion UNet"]
D --> F
F --> G["Denoised next frame x̂_t"]
G --> H["Reward/Termination model"]
H --> I["r̂_t, γ̂_t"]
G --> J["Actor-Critic"]
Key Components#
Component |
File |
Description |
|---|---|---|
|
|
Basic DDPM model and scheduler |
|
|
Diffusion Transformer |
|
|
Conditional UNet for DIAMOND |
|
|
EDM-style noise preconditioning |
|
|
Fast ODE-based sampling |
|
|
Reward and termination prediction |
|
|
Policy and value in imagination |
EDM Preconditioning#
DIAMOND uses the EDM (Elucidating Diffusion Model) formulation:
This ensures the model always receives inputs scaled to unit variance and predicts a scaled output that works well across all noise levels.
Sampling#
DIAMOND uses Euler sampling with very few steps (default 3) for fast inference:
x = noise * sigma_max
for sigma in sigmas[:-1]:
denoised = model(x, sigma, cond)
d = (x - denoised) / sigma
x = x + d * (sigma_next - sigma)
return denoised
Usage in TorchWM#
DiT quick start#
from torchwm import DiTConfig, get_dit_config
cfg = get_dit_config(DATASET="CIFAR10", BATCH=128, EPOCHS=100, IMG_SIZE=32)
DIAMOND quick start#
from world_models.configs.diamond_config import DiamondConfig
cfg = DiamondConfig(preset="small") # small, medium, large
cfg.game = "Breakout-v5"
cfg.obs_size = 64
DIAMOND CLI#
torchwm train diamond --config world_models/configs/experiments/diamond.yaml \
preset=small seed=1
Or directly:
python -m world_models.training.train_diamond --game Breakout-v5 --preset small
DIAMOND Training Loop#
for epoch in range(num_epochs):
# 1. Collect real experience
for step in range(environment_steps_per_epoch):
action = select_action(obs)
next_obs, reward, done = env.step(action)
buffer.add(obs, action, reward, done, next_obs)
obs = next_obs
# 2. Train diffusion world model
batch = buffer.sample(batch_size)
loss = train_diffusion_step(batch)
# 3. Train reward/termination model
loss_r = train_reward_model(batch)
# 4. Train actor-critic in imagination
for step in range(imagination_horizon):
action = actor(obs, hidden)
next_obs = diffusion_model(obs, action, cond)
reward = reward_model(next_obs)
hidden = update_hidden(hidden, action, next_obs)
actor_loss, critic_loss = compute_ac_loss(imagination_trajectory)
Config Reference#
DiTConfig#
Field |
Default |
Description |
|---|---|---|
|
32 |
Image resolution |
|
4 |
Patch size for tokenization |
|
384 |
Transformer embedding dimension |
|
6 |
Number of DiT blocks |
|
6 |
Number of attention heads |
|
128 |
Training batch size |
|
100 |
Training epochs |
|
1000 |
Diffusion timesteps |
|
1e-4 |
Noise schedule start |
|
0.02 |
Noise schedule end |
DiamondConfig#
Field |
Default |
Description |
|---|---|---|
|
|
Atari game name |
|
64 |
Frame resolution |
|
[64,64,64,64] |
UNet channel multipliers |
|
256 |
Conditioning embedding dim |
|
3 |
Euler sampling steps |
|
15 |
Actor-critic rollout length |
|
0.985 |
Discount factor γ |
|
1e-4 |
Learning rate |
|
1000 |
Total training epochs |
Sampling Methods#
Method |
Steps |
Quality |
Speed |
|---|---|---|---|
DDPM |
1000 |
Best |
Slow |
DDIM |
50–100 |
Good |
Fast |
Euler |
3–10 |
Fair for RL |
Very fast |
DPM-Solver |
10–20 |
Excellent |
Fast |
Comparison: DiT vs CNN-Based Diffusion#
Aspect |
U-Net (DDPM) |
DiT (Transformer) |
|---|---|---|
Architecture |
CNN with skip connections |
ViT |
Global attention |
Limited |
Full |
Scalability |
Medium |
High |
Quality |
Good |
Slightly better |
Compute |
Efficient |
Higher |
Common Pitfalls#
Slow sampling#
DDPM with 1000 steps is too slow for RL training loops.
Fixes:
Use Euler sampler with 3–10 steps (DIAMOND default)
Use DDIM for higher quality with ~50 steps
Training instability#
Diffusion UNets can produce NaN during training.
Fixes:
Enable gradient clipping
Use EDM preconditioning
Blurry generations#
Low sampling steps produce blurry results.
Fixes:
Increase
num_sampling_stepsAdd classifier-free guidance
Train with more diffusion timesteps
References#
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020.
Peebles, W., & Xie, S. (2023). Scalable Diffusion Models with Transformers. ICCV 2023.
Alonso, E., et al. (2024). DIAMOND: Diffusion as a Model of Environment Dreams. ICLR 2024.
Song, J., Meng, C., & Ermon, S. (2021). Denoising Diffusion Implicit Models. ICLR 2021.
Karras, T., et al. (2022). Elucidating the Design Space of Diffusion-Based Generative Models. NeurIPS 2022.